
Pavan Kumar Kandapagari
Model Deployment
I. Types of Deployment
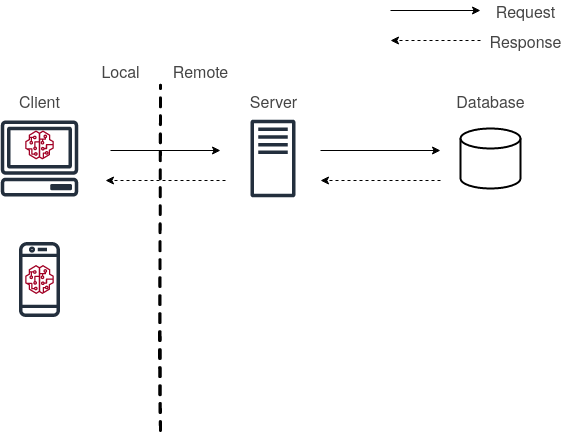
The overall ML/DL model can be conceptualized concerning deployment as a three-part system (client, server and database) for most intents and purposes. This setup can be visualized below so that we can differentiate all the types of deployment
Client - Server setup
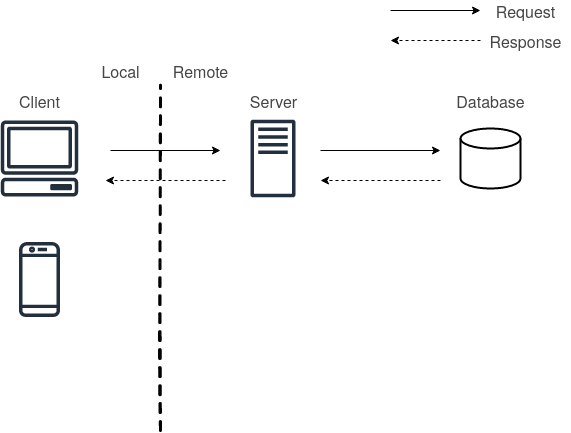
The first type of deployment we are going to address is Batch Prediction, but this can be a bit of a misnomer as batch prediction means that you train the models offline, dump the results in a database, and then run the rest of the application normally. Then once in a while, you run your model on new data incoming and cache the results into the database. When the client requests the results server retrieves them from the database and responds along to the client. Batch prediction is commonly used in production when the universe of inputs is relatively small (e.g., one prediction per user per day).
Batch Prediction Setup
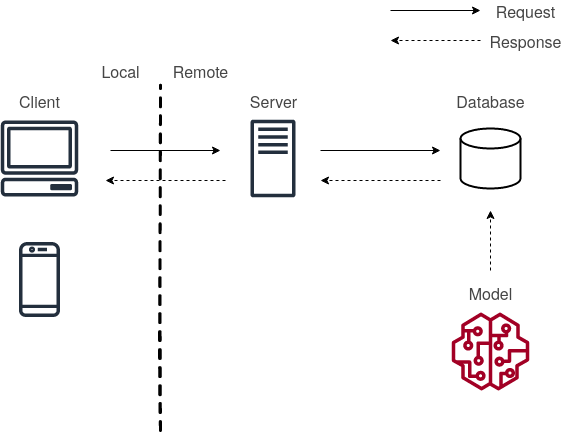
The next type of deployment is called Model-in-service which means that you package your model into the deployed web server itself. Then the web server loads the model and calls it to make the prediction. This type of deployment would make sense in a scenario where you already have a web server to use.
Model-in-Server Setup
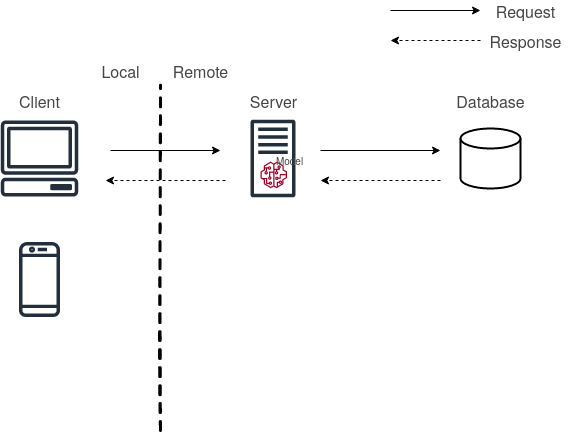
Here, Model-as-Service would mean that you deploy the model as its own service. The Client and/or service can interact with the model by making requests to the model service and receiving responses. This would mean a model can also be a micro-service.
Model-as-Service Setup
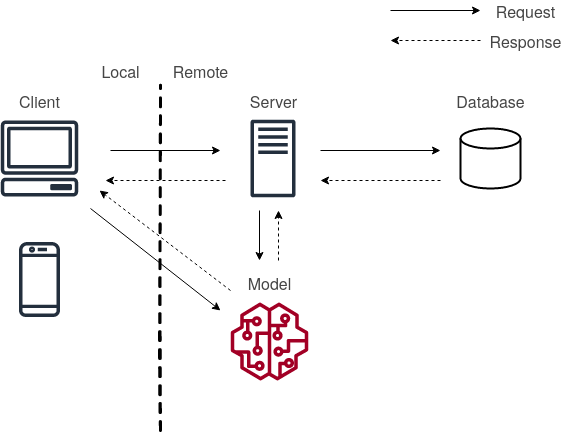
The final form of deployment is called Edge Deployment which means that you first send the model to the client edge device. Then the client loads the model and interacts with it directly.
Edge Deployment Setup
II. Building a Model Service
REST APIs
REST APIs () represent a way of serving predictions in response to canonically formatted HTTP requests. There are alternatives such as gRPC ( ) and GraphQL (). For instance, in your command line, you can use curl to post some data to an URL and get back JSON that contains the model predictions.
Sadly, there is no standard way of formatting the data that goes into an ML model. see , , .
It is also interesting to look at Knowledge sharing by Attila on Nov 4, 2022, here
DEPENDENCY MANAGEMENT
Three components need to produce reliable model predictions are the code, the model weights, and the code dependencies. These three things somehow need to be packaged into the service when you want to use your model as a service. The first two, code and weights can be either copied directly or using version control (or writing scripts to extract) into the service. But the dependencies are problematic as they cause a lot of trouble. They are hard to make consistent and update, and the model might behave differently accordingly.
Two high-level strategies might work for controlling the code dependencies:
For constraining the dependencies, you would need a standard neural network format. The (ONNX, for short) is designed to allow framework interoperability. The dream is to mix different frameworks, such that frameworks that are good for development (PyTorch) don’t also have to be good at inference (Caffe2).
The promise is that you can train a model with one tool stack and then deploy it using another for inference/prediction. ONNX is a robust and open standard for preventing framework lock-in and ensuring that your models will be usable in the long run.
The reality is that since ML libraries change quickly, there are often bugs in the translation layer. Furthermore, how do you deal with non-library code (like feature transformations)?
Containers are not only the future, they are the present! For this you need Docker. is a computer program that performs operating-system-level virtualization, also known as containerization. What is a container, you might ask? It is a standardized unit of fully packaged software used for local development, shipping code, and deploying system.
The best way to describe it intuitively is to think of a process surrounded by its filesystem. You run one or a few related processes, and they see a whole filesystem, not shared by anyone.
Note here that containers are different from virtual machines.
Docker framework
In brief, you should familiarize yourself with these basic concepts:
Furthermore, Docker has a robust ecosystem. It has the DockerHub () for community-contributed images. It’s incredibly easy to search for images that meet your needs, ready to pull down and use with little-to-no modification.
Though Docker presents how to deal with each of the individual microservices, we also need an orchestrator to handle the whole cluster of services. Such an orchestrator distributes containers onto the underlying virtual machines or bare metal so that these containers talk to each other and coordinate to solve the task at hand. The standard container orchestration tool is Kubernetes ().
PERFORMANCE OPTIMIZATION
We will talk mostly about how to run your model service faster on a single machine. Here are the key questions that you want to address:
Helpful libraries
The next, thing to do is Horizontal Scaling which is an extensive topic which deserves its own blog post.
III. Edge Deployment
TOOLS FOR EDGE DEPLOYMENT
MAKE EFFICIENT MODELS
Another thing to consider for edge deployment is to make the models more efficient. One way to do this is to use the same quantization and distillation techniques discussed above. Another way is to pick mobile-friendly model architectures. The first successful example is , which performs various downsampling techniques to a traditional ConvNet architecture to maximize accuracy while being mindful of the restricted resources for a mobile or an embedded device. by Yusuke Uchida explains why MobileNet and its variants are fast.
MINDSET FOR EDGE DEPLOYMENT
TAKEAWAYS
Next to follow Model Monitoring
IV. SOURCES
Stay Foxxy and much love.Pavan Kumar Kandapagari
Machine Learning, Deep Learning, NLP, Computer vision along with Software development enthusiast. Computer Engineer with a heart of a Mechanical Engineer.